我们经常比较两个模型哪个拟合更好, 比如在调节效应的分析中,
如果调节效应显著,我们就期望增加交互项应该可以提高模型的拟合度,
那么我们应该如何做呢?
一般我们有两种方法,通过卡方值的差异,检验差异是否显著;另一种是当没有卡方的时候,我们可以可使用对数似然值。
卡方差异检验
以下是使用Mplus进行卡方差异检验的步骤,包括使用MLM(Satorra-Bentler)、MLR和WLSM卡方。对于MLMV和WLSMV,应使用DIFFTEST。嵌套模型是较为严格的模型,其自由度大于比较模型。
- 计算差异检验缩放校正因子cd,其中d0是嵌套模型的自由度,c0是嵌套模型的缩放校正因子,d1是比较模型的自由度,c1是比较模型的缩放校正因子。请确保使用输出中给出的H0模型的校正因子。
cd = (d0 * c0 - d1 * c1) / (d0 - d1)
- 计算Satorra-Bentler缩放卡方差异检验TRd,如下所示:
TRd = (T0 * c0 - T1 * c1) / cd
其中T0和T1分别是嵌套模型和比较模型的MLM、MLR或WLSM卡方值。对于MLM和MLR,T0 c0和T1 c1的值与对应的ML卡方值相同。
使用对数似然进行差异检验
以下是基于使用MLR估计器获得的对数似然值和缩放校正因子来计算卡方差异检验的步骤。
- 使用MLR估计嵌套模型和比较模型。输出将分别给出H0模型和H1模型的对数似然值L0和L1,以及H0模型和H1模型的缩放校正因子c0和c1。
例如,
L0 = -2,606,c0 = 1.450,参数数量为39(p0 = 39)
L1 = -2,583,c1 = 1.546,参数数量为47(p1 = 47)
- 计算差异检验缩放校正因子,其中p0是嵌套模型的参数数量,p1是比较模型的参数数量。
cd = (p0 * c0 - p1c1)/(p0 - p1)
= (391.450 - 471.546)/(39 - 47) = 2.014
- 计算卡方差异检验(TRd)如下:
TRd = -2(L0 - L1)/cd
= -2*(-2606 + 2583)/2.014 = 22.840
案例 使用对数似然进行差异检验
下面是从一篇论文中找到一个对数似然进行差异检验的结果:
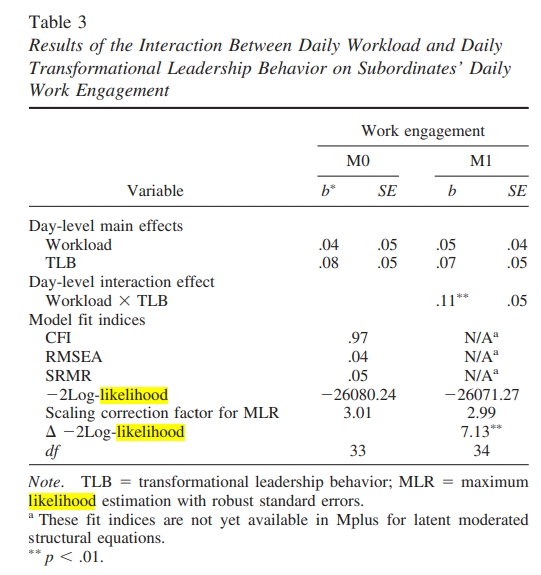
我们来地解释TRd=7.13这个数值是如何得到的。根据官方说明,我们首先需要计算差异测试缩放校正因子(cd),然后使用它来计算卡方差异测试(TRd)。
在论文中例子中,我们有以下信息:
- L0(H0模型的2Log-likelihood)是 -26080.24
- L1(H1模型的2Log-likelihood)是 -26071.27
- c0(H0模型的Scaling correction factor)是 3.01
- c1(H1模型的Scaling correction factor)是 2.99
- p0(H0模型的参数数量)是 33
- p1(H1模型的参数数量)是 34
首先,我们计算差异测试缩放校正因子(cd):
1 | cd = (p0 * c0 - p1 * c1) / (p0 - p1) |
接下来,我们使用这个缩放校正因子来计算卡方差异测试(TRd):
1 | TRd = -2 * (L0 - L1) / cd |
这里,我们得到的TRd值大约是7.69,而不是表格中呈现的7.13。这可能是因为原始数据存在轻微的差异,或者计算过程中存在四舍五入的情况。
如何根据TRD计算卡方显著性P值
在R中,如果你已经知道了卡方值和自由度,你可以使用pchisq()函数来计算显著性水平(p值)。
这个函数返回的是卡方分布在给定卡方值和自由度下的累积分布函数的值。
这个值可以被解释为观察到的卡方值出现的概率。
以下是使用pchisq()函数计算p值的示例:
1 | # 假设你的卡方值是 chi_square,自由度是 df |
在上面的代码中,1 - pchisq(chi_square, df)计算的是观察到的卡方值或更大值出现的概率,
这通常是我们关心的显著性水平。如果你关心的是观察到的卡方值或更小值出现的概率,你可以直接使用pchisq(chi_square, df)。
请注意,这个计算假设你的数据符合卡方分布。如果数据不符合这个假设,那么计算出的p值可能不准确。在使用卡方检验时,还需要注意其他假设和限制条件,比如样本大小、独立性等。