Heckman两阶段回归的中文名字是赫克曼两阶段回归。
这是经济学中解决选择偏误问题的统计方法,常用于解决样本选择偏误导致的有偏估计问题。其基本原理包括两个阶段:样本选择模型(回归样本为一个子样本)和处理效应模型(回归模型中包含一个内生的指示变量D)。
背景
这是我们见到的最简单的一个回归模型:
$$ \mathbf{y^*=xb + \epsilon} $$
为了解决这个问题,Heckman 发明了 样本选择的两阶段回归(赫克曼两阶段回归),这个算法让他获得了诺贝尔经济学奖,但是这个模型并不复杂, 你在这篇文章中就可以学fei。
样本选择机制
假设,样本的缺失是可以被预测的, 简单说就是有如下模型:
$$ \mathbf{z}^* = \mathbf{w}\gamma + \mathbf{u} $$
$w$是一个变量,$\gamma$ 是系数,预测值$\mathbf{z}^*$ 用于样本的选择:
$$ \begin{split}\begin{align} z_i =& 1 \text{ if } z^*_i > 0 \\ =&0 \text{ if } z^*_i \le 0 \end{align}\end{split} $$
这里我假设你们学习过正态分布,那么你就懂得$\Phi(a)$的意思是x服从正态分布,那么x值小于a的概率就是$\Phi(a)$。
因为我们假定$\mathbf{u}$符合正态分布,即$\mathbf{u}\sim N(\mathbf{0},\mathbf{I})$
这里需要解释一下, 正态分布是对称的(对称轴是x=0),如图:
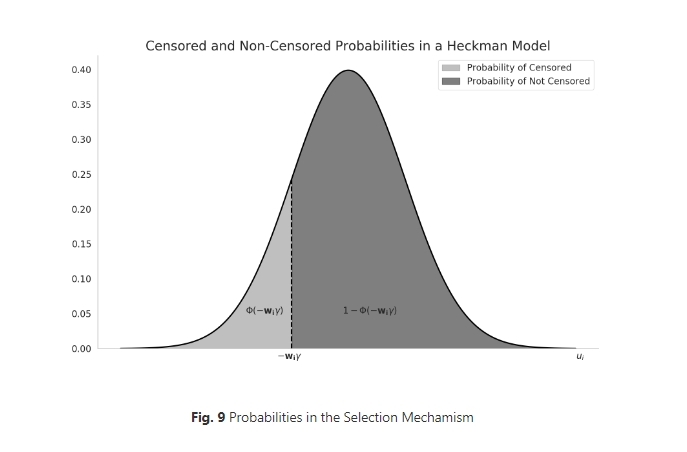
$\Phi(a)$ 就是x小于a的概率, 那么这个值与x大于-a的概率是一样的,所以$\Phi(a)=1-\Phi(-a)$
样本选择偏差
现在考虑到了样本选择是有偏差的, 那么我们可以构建我们真正关心的模型:
$$ y_i = y^*_i = \mathbf{x}_i \beta + \epsilon_i \text{ observed, if = 1} $$
$$ \begin{split}\begin{align} z_i =& 1 \text{ if } z^*_i > 0 \\ =&0 \text{ if } z^*_i \le 0 \end{align}\end{split} $$
因为残差就是变量, 我们现在其实有两个残差, 一个是来自样本选择模型($u_i$), 一个是量化模型(我们真正关心的回归模型)($\epsilon_i$),
我们必须对这两个变量做一些规定,否则模型无法估计,两个变量假定服从联合正态分布:
$$ \begin{split}\begin{equation} \begin{bmatrix} u_i \\ \epsilon_i \end{bmatrix} \sim Normal\left( \begin{bmatrix} 0 \\ 0 \end{bmatrix}, \begin{bmatrix} 1 & \rho \\ \rho & \sigma^2_\epsilon \end{bmatrix} \right) \end{equation}\end{split} $$
注意上面的$\rho$,它是相关系数, 但也可以说是协方差,因为标准数据的协方差就是相关系数。
不考虑样本偏差的情况下,我们根据最小二乘法知道, y的期望: $E(y_i)=\mathbf{x}_i\beta$ , 但是现在加入了一个样本选择模型,
那么我们可以计算得到新的y的期望的计算公式:
$$ \begin{split}\begin{align} E(y_i | y_i \text{ observed}) = & E(y_i | z^* > 0 ) \\ =&E(y_i | u_i > -\mathbf{w}_i \gamma) \\ =&\mathbf{x}_i \beta + E(\epsilon_i | u_i > -\mathbf{w}_i \gamma) \\ =&\mathbf{x}_i \beta + \rho \sigma_\epsilon \frac{\phi(\mathbf{w}_i \gamma)}{\Phi(\mathbf{w}_i \gamma)} \end{align}\end{split} $$
参数估计
Heckman两阶段模型有两个方程式,估计里面的参数用到了极大似然估计,
而极大似然估计法最关键的是优化参数得到最优的似然值,所以我列出来极大似然的对数值,这来自stata介绍Heckman Model的相关文档。
$$ \begin{split}\begin{equation} \small C_i = \left\{ \begin{aligned} &ln\Phi \left(\frac{\mathbf{w_i \gamma} + \rho \left (\frac{y_i - \mathbf{x}_i \beta}{\sigma_\epsilon}\right)} {\sqrt{1 - \rho^2}}\right) - \frac{1}{2} \left( \frac{y_i - \mathbf{x}_i\beta}{\sigma_{\epsilon}} \right)^2-ln\left(\sigma_{\epsilon}\sqrt{2\pi}\right) \text{, $z_i$ = 1}\\ &ln\left( 1 - \Phi(\mathbf{w}_i\gamma) \right) \text{, $z_i$ = 0} \end{aligned} \right. ; LogL = \sum_{i = 1}^N C_i \end{equation}\end{split} $$
实验
为了进一步理解Heckman两阶段回归,我们做一个模拟实验,生成几种样本, 观察这些样本对量化模型中参数$b$
1 | import numpy as np |
1 | import matplotlib.pyplot as plt |
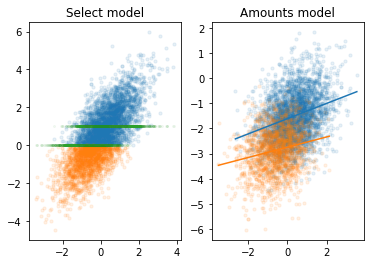
使用Python做Heckman分析
这个heckman的代码是来自于python著名的统计库statsmodels,但是代码并没有合并到主分支里,所以只能从这个地方下载。
1 | import heckman as heckman |
Heckman Regression Results ======================================= Dep. Variable: y Model: Heckman Method: Heckman Two-Step Date: Tue, 31 Oct 2023 Time: 10:44:53 No. Total Obs.: 5000 No. Censored Obs.: 1829 No. Uncensored Obs.: 3171 ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ Constant -2.0004 0.039 -51.658 0.000 -2.076 -1.925 Slope 0.5079 0.024 20.793 0.000 0.460 0.556 ======================================================================================== coef std err z P>|z| [0.025 0.975] ---------------------------------------------------------------------------------------- Constant (Selection) 0.4716 0.021 21.966 0.000 0.430 0.514 Slope (Selection) 0.9510 0.027 35.323 0.000 0.898 1.004 ================================================================================ coef std err z P>|z| [0.025 0.975] -------------------------------------------------------------------------------- IMR (Lambda) 0.7922 0.064 12.336 0.000 0.666 0.918 ===================================== rho: 0.794 sigma: 0.998 ===================================== First table are the estimates for the regression (response) equation. Second table are the estimates for the selection equation. Third table is the estimate for the coef of the inverse Mills ratio (Heckman's Lambda).
Heckman两阶段回归的stata代码
1 | %%stata -d stata_data |
视频教程
注意
统计咨询请加QQ 2726725926, 微信 shujufenxidaizuo, SPSS统计咨询是收费的, 不论什么模型都可以, 只限制于1个研究内.
本文由jupyter notebook转换而来, 您可以在这里下载notebook
可以在微博上@mlln-cn向我免费题问
请记住我的网址: mlln.cn 或者 jupyter.cn