APIM是 Actor-Partner Interdependence Model 的简称,
下图是用于表示APIM的常用概念图, 今天我们将要从介绍概念开始,
带你理解APIM及其使用条件, 然后使用mplus做APIM的分析,
如果你没有学习过mplus, 不用担心, 我们尽量让教程保持简单, 适合刚入门的学生。
如果你只会SPSS, 我们可以补充SPSS的教程(使用混合线性模型), 目前还在策划。
介绍
社会科学研究通常关注个人对彼此的影响。然而,在处理涉及人际关系的研究问题时,如果使用不适当的统计方法和工具,可能会产生重大错误和误解。
Actor-Partner Interdependence Model (APIM) 是最流行的用于处理配对数据的模型。 本文介绍了如何使用结构方程建模 (SEM) 检验 APIM 的分步教程。
在详细说明我们的逐步教程之前,将简要介绍关键的对偶数据假设和概念问题。此外,还将介绍 APIM 及其最新发展(主客体互依/互倚中介效应、主客体互依/互倚调节效应)。
2种方法
目前可以分析APIM成对数据的方法有2种, 分别是:使用多层模型, 比如SPSS的Mixed命令可以构建混合线性模型, 这种方法不是我们这篇文章要介绍的方法,
你可以看这篇《SPSS做主客体互依模型APIM–使用混合线性模型》,
需要注意的是, 这种方法的数据结构是不同的; 另外更常用的方法是使用结构方程模型(SEM), Amos和Mplus是最常用的软件, 这种方法的数据结构与前一种方法不同,
这里我们仅介绍使用SEM做APIM分析的方法, 至于第一种方法, 我们会在另外的教程中介绍。
案例
我们用案例来理解概念是最高效的方式, 所以我们先介绍一个简单的案例,
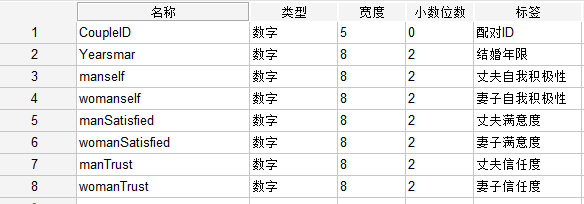
下图是SPSS数据的截图, 这个是变量视图, 你可以看到我们有很多变量,
为了简单起见, 我们先介绍一个简单的模型, 以自我积极性为自变量,
以婚姻满意度为因变量 , 构建构建主客体互依模型(APIM),
这样, 我们就有4个变量:
- manself : 丈夫自我积极性
- womanself : 妻子自我积极性
- manSatisfied : 丈夫婚姻满意度
- womanSatisfied : 妻子婚姻满意度
根据上面的案例, 我们可以构建APIM模型如下:
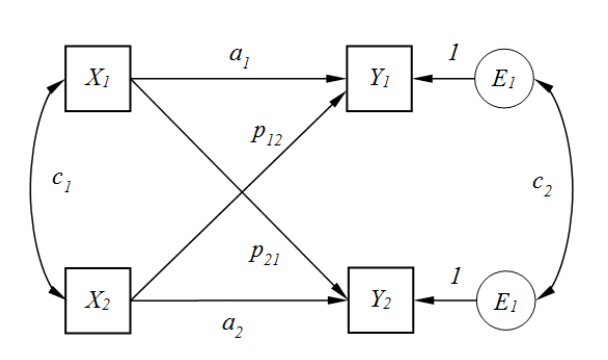
图中数字1代表丈夫, 2代表妻子, X代表自变量自我积极性, Y代表因变量满意度。
对偶数据(Dyadic data)
什么是对偶数据
对偶数据可以理解为配对数据, 对偶数据是社会关系中最基础的一种关系, 比如配偶、朋友、父子、母女、雇主、竞争关系。
在上面的案例中, 我们的样本是148对儿夫妻, 丈夫和妻子都填写相同的问卷,
对于丈夫来说, 妻子是客体, 对于妻子来说, 丈夫是客体,
你可以看到, 我们的数据有148行数据, CoupleID(配对ID)这个变量就是夫妻的编码, 丈夫和妻子共享同样的配对ID。
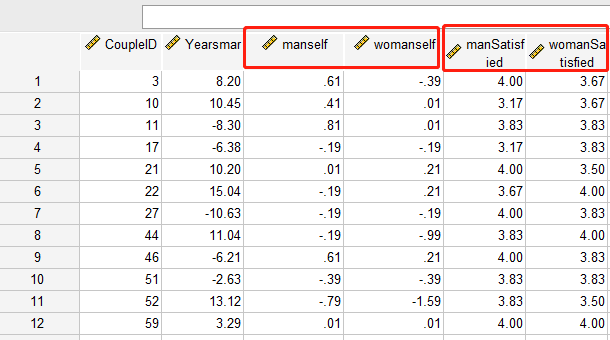
从上图中, 红框的数据属于一对变量, 对于妻子, 丈夫是客体;
对于丈夫恰好相反, 妻子是客体。
像上面这样的数据, 就是对偶数据。 注意如果你使用SPSS的混合线性模型分析对偶数据,
数据的格式将发生很大变化, 目前的数据格式是用于结构方程模型的APIM分析的。
图中所示的数据结构属于宽数据格式, 于此对应的是长数据格式。
The Actor-Partner Interdependence Model APIM模型介绍
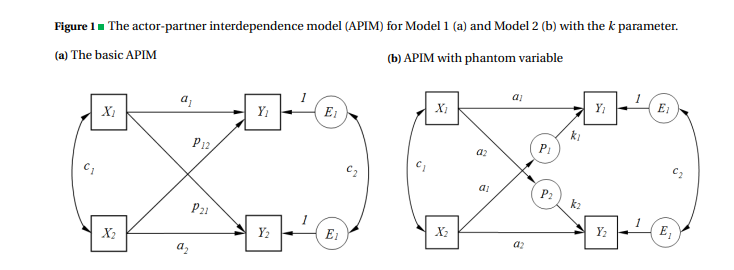
我们看上图就是APIM模型图, 这个图可以分为几个部分来看(X1 X2 Y1 Y2 分别表示案例数据中的 manself womanself manSatisfied womanSatisfied
- 主体效应, X1对Y1的影响, 用路径系数a1表示; X2对Y2的影响, 用路径系数a2表示;
- 客体效应, X1对Y2的影响, 用p21表示; X2对Y1的影响, 用p12表示;
- 相关: 由于是配对数据, X1和X2大概率是相关的, 用c1表示; 同样c2表示Y1和Y2;
APIM模式
定义了主客体效应, 根据他俩之间的关系可以将对偶模式定义为四种:
- 主体模式: 主体效应显著, 客体效应不显著, 因变量主要受到主体效应的影响, p/a≈0
- 客体模式: 主体效应不显著, 客体效应显著, 因变量主要受到客体效应的影响, a≈0 p≠0
- 对偶模式: 主体效应显著, 客体效应显著, 因变量受主客体效应的影响, p≠0 a≠0 p/a≈1
- 对比模式: 主客体效应显著, 但是两者符号相反, p+a≈0
K参数
在早期, 我们就根据参数a1 a2 p1 p2的显著性就可以判断对偶模式, 但是这不严谨。
在APIM中,如果只检验主体效应和客体效应的显著性从而推出模型为主体模式、客体模式、对偶模式或对比模式的结论比较危险。
比如研究者可能发现主体效应或客体效应是显著的,从而认为是主体模式或客体模式,但该模式其实可能应为对偶模
式;比较极端的现象是,主体效应与客体效应都是不显著的,但APIM的模式仍可能为对偶模式(Kenny& Ledermann, 2010)。
因此, Kenny等人提出了对APIM的模式进行检验的方法,并将其中涉及的检验参数命名为k以表示对成对关系研究先驱Larry
Kurdek的敬意( Kenny & Ledermann, 2010)。
目前我们的模型中有两个主体效应和客体效应, 因此需要定义两个k:
1 | k1 = p12/a1 |
由于k值计算的时候, 需要用除法, 我们如果确定主体效应不为0, 那可以顺利计算k;
但是很多时候我们不能知道主体效应是否为0, 所以我们往往是构建一个包含幽灵变量的模型(右侧), 如下:
这个模型增加了潜变量P1和P2, 他们对模型没有任何影响, 因此叫做幽灵变量;
但是k1就是P1到Y1的路径系数, 只要我们固定X2到P1的路径系数为a1, 那么p12=k1a1,
因为幽灵变量不影响X2对Y1的效应大小, 所以你对比上图中两个模型, 左图中p12就是X2对Y2的效应,
右图中, k1a1就是X2对Y2的效应, 注意这里的a1的意义是X2->P1的效应。
你可以能不理解这个推理过程, 建议你暂时忽略, 等你有了更多结构方程的经验, 再回头看。
可区分不可区分成对数据
实际上任何模型都是越简单越好, 也就是说参数越少越好,
在我们的APIM模型中, 如果数据是不可区分的配对, 比如同性恋中两个人是不可区分的,
而异性恋中可以使用性别对配对双方进行区分。
在不可区分配对数据中, 由于配对双方没有明显区别, 所以模型中两个主体效应和客体效应是相等的, 即:
a1=a2、p1=p2, 这种情况下k1=k2, 这时候模型的参数就大大减少了; 值得注意的是, 即便你的数据是可区分配对数据,
但是通过检验a1和a2是否相等, p1和p2是否相等, 你仍然可以认为数据是配对不可区分的, 这时候你的模型中的参数就可以减少。
APIM 结构方程模型的分析流程
Mplus做APIM模型分析
在分析可区分的成对数据时,Kenny等人建
议遵循如下步骤进行检验:
- 第一步,检验对偶是否可分
- 第二步,计算k值及其置信区间, 进而可以判断夫妻的APIM模式,
如果置信区间中包含1, 说明主客体效应相等, 但是如果主客体效应都显著, 那就是对偶模式;
如果置信区间包含-1, 且住壳体效应都显著, 那就是对比模式。
如果置信区间包含0, 且主效应显著, 那就是主体模式;反之为客体模式
第一步, 检验配对数据是否可分
构建无限制模型
我们直接上Mplus代码, 在代码中加注释, 讲解每个命令的含义。
你需要注意, 注释就是英文叹号“!”后面的内容, 注释是代码中不会被运行的, 帮助人们阅读代码的。
1 | TITLE: actor-partner interdependence model; ! 这是标题 可以随意设置 |
以上代码想要用到你的数据中, 你需要确保数据文件格式正确, 文件名设置为你自己的文件名;
这个代码的目的是计算a1 p1 a2 p2的估计值, 及其置信区间,
你要注意, 当a1和a2过小, k1=p1/a1, 这时候k1可能达到无限大, 这提示我们成对模式可能是客体模式,
我们的软件无法处理无限大的问题, 所以会出现计算错误, 因此可以计算k1的倒数, k1的倒数接近0, 这不会引发错误。
构建限制模型 a1=a2 b1=b2
我们将代码稍作修改, 就可以得到不可区分的模型:
该方法在模型中限制6个相等:预测变量的均数和方差相等、因变量的截距相等、误差方差相
等、主体效应相等、客体效应相等。限制相等后,该模型也可称为可交换的饱和( interchangeable and saturated, ISAT)模型。
1 | TITLE: actor-partner interdependence model; ! 这是标题 可以随意设置 |
如果有限制模型与无限制模型的拟合指标没有显著差异(卡方差值不显著)就可以选择限制模型;
因为限制模式参数少, 简化了模型, 模型约简化越好。
由于成对关系不可区分, 所以妻子和丈夫的主客体效应参数名称相同。
经过这个步骤, 你应当确认了我们的模式是否是客体模式, 如果是, 后续分析使用k的倒数代替k。
第二步: 计算k
很多文献建议构建带有幽灵变量的APIM模型, 为了保持一致, 我们也这样做, 但是应当告诉你这不是必要的,
我们在视频教程中会讲解为什么幽灵变量没有必要。
下面是mplus代码:
无限制模型
如果你的数据是不可区分的配对关系, 那就要使用无限制模型,由于其他代码没有变, 我们主要提供需要你更改的代码:
1 |
|
有限制模型
1 | MODEL: P1 by Y1*(k); ! "*" 取消固定为1 |
固定k模型
如果k的置信区间包含0, 可以固定k值, 用于检验这种模型拟合是否达标。
1 | MODEL: P1 by Y1@0(k1); !"@" is used for fixing a parameter with a value |
使用R语言做APIM
我们还有一篇文章介绍, 如何使用R做主客体相倚APIM分析, 点击传送门:《R语言做主客体相依模型包括混合线性模型MIXED和结构方程模型SEM》。
视频教程
参考文献
https://randilgarcia.github.io/week-dyad-workshop/index.html
注意
统计咨询请加QQ 2726725926, 微信 shujufenxidaizuo, SPSS统计咨询是收费的, 不论什么模型都可以, 只限制于1个研究内.
跟我学统计可以代做分析, 每单几百元不等.
本文由jupyter notebook转换而来, 您可以在这里下载notebook
可以在微博上@mlln-cn向我免费题问
请记住我的网址: mlln.cn 或者 jupyter.cn