层次线性模型有很多名字,比如混合效应模型,多层线性模型,层次回归模型等等。
本篇介绍层次线性模型的逻辑。我们从一个简单的例子开始,这个例子建立在读者对回归和方差分析(ANOVA)中熟悉的概念的理解之上。
一元线性回归模型
我们首先考虑单个学生层面的预测变量(例如,社会经济地位[SES])与一个学生层面的结果变量(数学成就 Achivement)在一个假设学校内的关系。
我们假设,学生层面的结果变量(Achivement)是一个线性函数,其系数为β1,截距为β0,残差为ε。
那么公式如下:
$ \text{Achivement} = \beta_0 + \beta_1 \cdot \text{SES} + \epsilon_i $
我们用X表示自变量,Y表示因变量,以上公式可以形式化为:
$$ \begin{aligned} Y_i = \beta_0 + \beta_1 \cdot X_i + \epsilon_i \end{aligned} $$
用散点图表示:
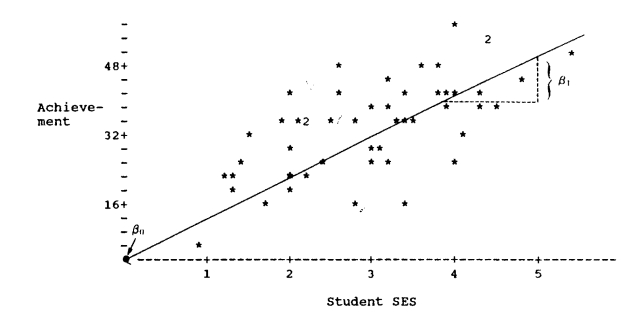
通常我们会对自变量进行中心化,即自变量减去其均值$X_i-\bar X$, 这样中心化可以赋予截距β0一个特殊的含义。例如中心化后,我们可以看到下面的散点图:

最终截距β0的含义是因变量的均值,即当自变量X为0时,因变量取均值。
假如我们分析两个学校的数据, 分别绘制散点图,分别拟合回归线,得到下面的图像:
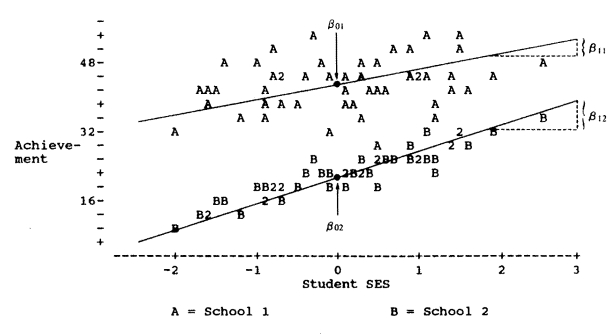
这时候我们可以比较两个截距β0,发现两个学校中,学校A的截距β01远远高于学校B的截距β02。注意截距的含义就是当自变量取0时,因变量取均值。所以可以看出学校A的平均学生成绩高于学校B的平均学生成绩。从斜率可以看出,当学生的社会经济地位(SES)提高时,学生成绩也会提高。但是比较两个学校发现,SES变化一个单位,学校A的学生成绩变化比较小,说明学校A的学生成绩受到SES的影响较小。
J个学校的情况
我们现在考虑J个学校的数据,每个学校的数据都包含N个学生的数据。我们仍然假设,学生层面的结果变量(Achivement)是一个线性函数,其系数为β1,截距为β0,残差为ε。对于学校j的模型,就是:
$$ \begin{aligned} Y_{ij} = \beta_{0j} + \beta_{1j} \cdot X_{ij} + \epsilon_{ij} \end{aligned} $$
我们观察到β1和β0都带有角标j,它意味着这些参数随着学校的变化而变化,所以他们实际上是变量。而变量都有期望和方差,我们增加了如下参数:
$$ E(\beta_{0j}) = \gamma_0 \\ Var(\beta_{0j}) = \tau_0 \\ E(\beta_{1j}) = \gamma_1 \\ Var(\beta_{1j}) = \tau_1 \\ Cov(\beta_{0j},\beta_{1j}) = \rho_{01} $$
我们需要了解这几个参数,因为在大部分多水平的建模软件里,可能都会出现他们的名字,
让很多小白用户感到困惑。
如果我们假设所有的学校共享同样的截距和斜率,那么这个模型就退回到前面的一元线性模型。
这时候截距的期望就是因变量的均值,而截距的方差就是0,那么这些参数也就是已知的了。
没有自变量X的随机截距模型
当模型中不包含自变量的时候,写作:
$$ \begin{aligned} Y_{ij} = \beta_{0j} + \epsilon_{ij} \end{aligned} $$
在这个模型中,我们使用β0j加上一个误差来预测因变量Y, 那么β0j怎么样参能对Y有最佳预测准确度,也就是误差最小呢?通过最小二乘法可以计算出,当β0j取学校的学生平均Y值的时候,对Y有最佳的预测,误差最小。所以当你估计出来截距β0j的时候,就可以认为这个截距就是j学校学生的均值。
现在这个模型就叫做随机截距模型。
引入学校层面变量
变量$W_j$指的是学校是否是私有的,我们按照常识推断,私人学校可能比公办学校平均成绩更高。在我们的模型里,哪个参数代表了学校的平均成绩?β0j。
我们可以假设:
$$ \beta_{0j} = \gamma_0 + \gamma_1 W_j $$
带入前面的模型,我们可以得到:
$$ Y_{ij} = \gamma_0 + \gamma_1 W_j + \epsilon_{ij} $$
这是一个不太靠谱的模型,因为我们对成绩Y的预测,仅仅依赖学校是否私有这一个变量,
学校是私有的,则相对的成绩会高一些, 但是一个学校里的所有学生都会预测为一个值,然后加上一个随机的误差$\epsilon_{ij}$.
现在这个模型就是一个随机截距模型,并且还引入了一个学校层面的变量对随机的截距进行预测。
随机斜率模型
前面的模型没有考虑随机截距,下面考虑自变量X对因变量Y的影响是随学校的不同而不同的, 那么有如下模型:
$$ Y_{ij} = \beta_{0j} + \beta_{1j} X_{ij} + \epsilon_{ij} $$
现在先不考虑变量W,我们有如下假定:
$$ \beta_{0j} = \gamma_{00} + \mu_{0j} \\ \beta_{1j} = \gamma_{10} + \mu_{1j} $$
$\gamma_{00} \gamma_{01}$ 是一个常数, 代表截距和斜率的平均值,$\mu_{0j}$ 和 $\mu_{1j}$ 是随机变量, 它们都有角标j,说明他们都是随着学校的不同而变化的,代表不同学校的截距和斜率偏离均值的大小。 如果你在一些统计软件里见到$\gamma$你就应该知道它是截距和斜率的平均值。但是你不会见到$\mu$这个参数,因为它是变量,它有均值和方差,以及他们之间的协方差,我们定义如下:
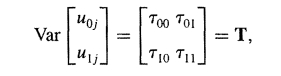
$tau_{00}$: 截距的方差$tau_{11}$: 斜率的方差$tau_{01}$: 截距的协方差
这些参数在很多多水平混合效应建模软件中都可能出现。 因为我们是多水平建模,我们期望方差都是显著的,
因为方差不显著就是0,方差为0就是常数,是在组间不变的,如果截距和斜率在组间不变,那么我们失去了做多水平建模的必要性。
引入学校层面的变量
我们假定变量W对截距和斜率有影响,如:
$$ \beta_{0j} = \gamma_{00} + \gamma_{01} W_j + \mu_{0j} \beta_{1j} = \gamma_{10} + \gamma_{11} W_j + \mu_{1j} $$
在模型中,替换掉截距和斜率可得下面的模型:
$$ Y_{ij} = (\gamma_{00} + \gamma_{01} W_j + \mu_{0j}) + (\gamma_{10} + \gamma_{11} W_j + \mu_{1j}) X_{ij} + \epsilon_{ij} $$
化简以后:
$$ Y_{ij} = \gamma_{00} + \gamma_{01} W_j + \mu_{0j} + \gamma_{10} X_{ij} + \gamma_{11} W_j X_{ij} + \epsilon_{ij} $$
变量中心化
我们知道,截距就是自变量取值为0时,因变量的值。 但是如果你的自变量取值范围不包括0,截距是毫无意义的。但是变量中心化以后,自变量取值为0时,就是中心化前的平均值,截距就是自变量取均值时因变量的值,实际上也是因变量的期望。所以中心化的好处就显而易见。
前面提了一嘴变量的中心化,不管是多层模型还是其他模型,变量的中心化主要目的就是提高参数的可解释性。
这篇文章不会深入的解释其中的原理,只是简单的介绍。
中心化主要有两种方式:变量减去全部样本均值(grandmean)和变量减去所在组均值(groupmean)。
grandmean
假如我们有多个学校的学生样本,X变量的所有样本均值是$\bar X$ , 那么grandmean就是$X-\bar X$ .
在grandmean的情况下, 截距有如下表达式:
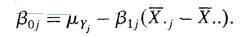
$\mu_{Yj}$是第j个学校学生的因变量均值。 所以每个学校的截距就是每个学校的因变量均值,再减去斜率与总体均值与学校均值差的乘积。
groupmean
假如我们有多个学校的学生样本,X变量的各学校样本均值是$\bar X_j$ , 那么 groupmean 就是$X-\bar X_j$ .
这种情况下, 截距就是所在学校的因变量均值:
